




Nvidia continues to solidify its leadership in the AI accelerator market, with new tests demonstrating the immense power of its latest products. A recent comparison of the new Blackwell Ultra GB300 rack module against the GB200 in long-context DeepSeek workloads revealed that the new solution is in a class of its own, delivering a significant performance leap.

LMSYS Benchmarks Underscore Generational Leap
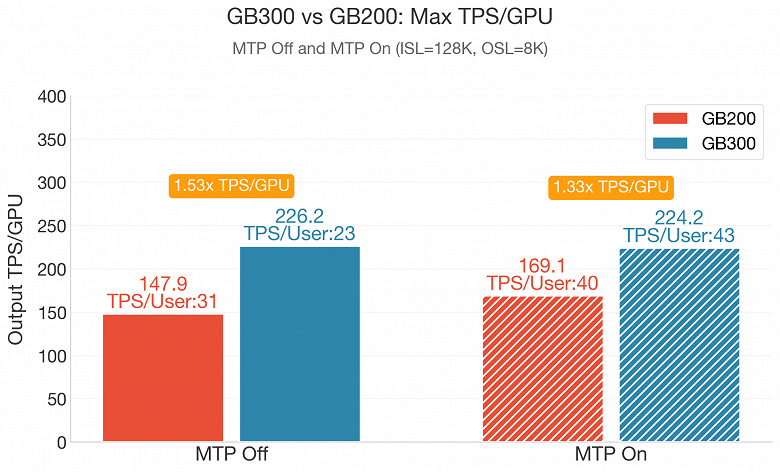
The Large Model Systems Organization (LMSYS) tested the GB300 NVL72 system in long-context inference scenarios, a key area of optimization for Nvidia’s new solution. The results are compelling, showing a performance increase of 33-53% over the previous generation, a remarkable gain considering the underlying architecture remains the same. Furthermore, the overall request processing speed saw a massive 1.87x improvement. These benchmarks confirm that the GB300 architecture is exceptionally well-suited for hyperscale deployments that require high responsiveness and sustained long-context performance.
What’s Under the Hood of Blackwell?
The Blackwell architecture, officially announced in March 2024, is the successor to the Hopper and Ada Lovelace microarchitectures. The GB300 NVL72 is a fully liquid-cooled, rack-scale system that integrates 72 Blackwell Ultra GPUs and 36 Arm-based Grace CPUs into a single, cohesive platform. This design is built to power the next generation of AI, particularly trillion-parameter models. Key innovations include a second-generation Transformer Engine and a new 4-bit floating point (FP4) AI capability, which doubles the performance and size of models that can be supported while maintaining high accuracy.
Market Context and the Competitive Landscape
Nvidia remains the dominant force in the AI hardware sector. However, the competitive field is evolving rapidly. AMD has emerged as a strong challenger with its Instinct MI300 series, while Intel is making strides with its Gaudi line of accelerators. Additionally, major cloud providers like Google (TPUs) and Amazon (Trainium/Inferentia) are developing their own custom chips to reduce reliance on third-party vendors and optimize for their specific workloads. Despite these challenges, Nvidia’s comprehensive ecosystem, including its CUDA software platform, provides a significant competitive advantage that is difficult for others to replicate.
A Look to the Future: Total Cost of Ownership and Industry Impact
While the initial investment for a GB300 NVL72 rack is substantial, estimated at over $3 million, Nvidia and industry analysts argue that the platform’s superior performance and energy efficiency will lead to a lower total cost of ownership (TCO) over time. According to some reports, the GB300 platform can deliver up to 35x lower cost per token compared to the previous Hopper platform for certain workloads. As the first Blackwell GB300 systems begin to ship, the key question is not just about raw performance, but what new AI capabilities become possible with this level of compute power. This advancement is expected to drive the next wave of AI development, enabling more complex models and real-time applications that were previously not economically viable.



